
🌭MongoDB 基本概念详解
官方网址: 👉 官方文档: 👉
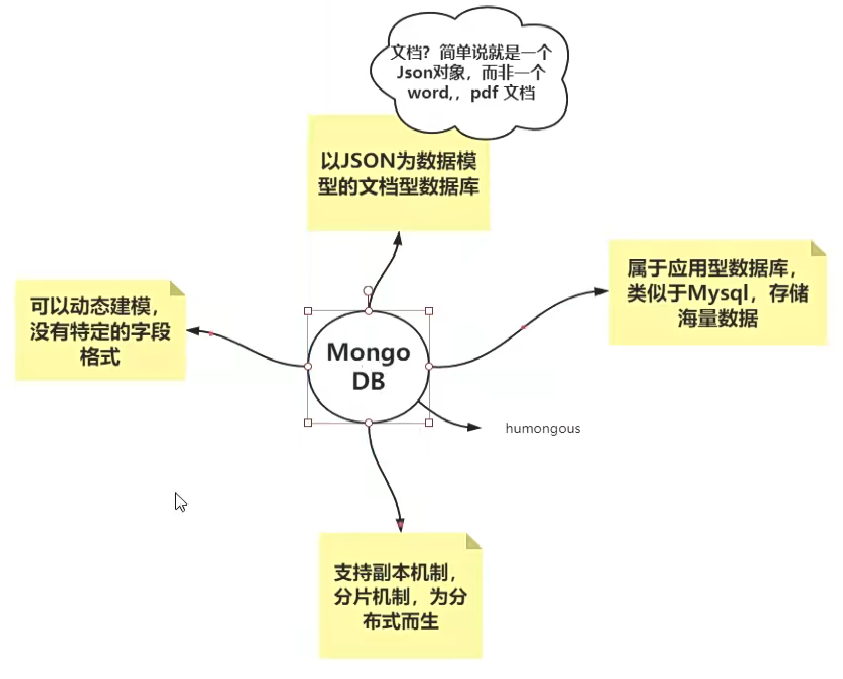
1️⃣Mongo是什么?
Mongo 是 humongous 的中间部分,在英文里是“巨大无比”的意思。所以 MongoDB 可以翻译成“巨大无比的数据库”,更优雅的叫法是“海量数据库”。Mongodb是一款非关系型数据库,说到非关系型数据库,区别于关系型数据库最显著的特征就是没有SQL语句,数据没有固定的数据类型,关系数据库的所使用的SQL语句自从 IBM 发明出来以后,已经有 40 多年的历史了,但是时至今日,开发程序员一般不太喜欢这个东西,因为它的基本理念和程序员编程的想法不一致。后来所谓的 NoSQL 风,指的就是那些不用 SQL 作为查询语言的数据存储系统,而文档数据库 MongoDB 正是 NoSQL 的代表。
2️⃣MongoDB都有哪些特点?
1.MongoDB中的记录是一个文档,它是由字段和值对组成的数据结构。MongoDB文档类似于JSON对象。字段的值可以包括其他文档,数组和文档数组。MongoDB数据模型和你的对象在内存中的表现形式一样,一目了然的对象模型。
{
name: "ralph",
age: 18,
jobs: "Devops"
}
2.同一个集合中可以包含不同字段(类型)的文档对象:同一个集合的字段可能不同
3.线上修改数据模式,修改时应用与数据库都无须下线
3️⃣MongoDB和关系型数据库的差异
关系型数据库和文档型数据库主要概念对应
| 关系型数据库 | 文档型数据库 | |
|---|---|---|
| 模型实体 | 表 | 集合 |
| 模型属性 | 列 | 字段 |
| 模型关系 | 表关联 | 内嵌数组,引用字段关联 |
| 横向扩展能力 | 需要插件 | 原生支持数据分片 |
| 高可用 | 集群 | 复制集 |
4️⃣MongoDB部署和常用命令
1.Mongodb的单机部署
请直接跳转CSDN博客,网上大把 👉
跨IP连接数据库
如果在本机使用的都是默认参数,也可以直接忽略所有参数 ,如果是不同ip使用一下方式
mongo --host <HOSTNAME> --port <PORT>
设置用户密码
use admin # 设置密码需要切换到admin库
db.createUser(
{
user: "ralph",
pwd: "123456",
roles: [ "root" ]
}
)
show users # 查看所有用户信息
db.shutdownServer() # 停掉服务
登录
# 以授权模式启动
mongod --auth
# 授权方式连接
mongo -u ralph
2.UI界面的设置

3.常用命令
可以使用help 来进行具体的查看
> help
db.help() help on db methods
db.mycoll.help() help on collection methods
sh.help() sharding helpers
rs.help() replica set helpers
help admin administrative help
help connect connecting to a db help
help keys key shortcuts
help misc misc things to know
help mr mapreduce
show dbs show database names
show collections show collections in current database
show users show users in current database
show profile show most recent system.profile entries with time >= 1ms
show logs show the accessible logger names
show log [name] prints out the last segment of log in memory, 'global' is default
use <db_name> set current database
db.mycoll.find() list objects in collection mycoll
db.mycoll.find( { a : 1 } ) list objects in mycoll where a == 1
it result of the last line evaluated; use to further iterate
DBQuery.shellBatchSize = x set default number of items to display on shell
exit quit the mongo shell
创建一个叫demo的数据库
> use demo
switched to db demo
再次创建一个叫做members的集合 == [创建一个叫做members的表]
同时插入文档 == [数据] 通过tab 可以通过命名发现 插入一条or 插入多条数据
> db.members.insert
db.members.insert( db.members.insertMany( db.members.insertOne(
具体的作用和使用方式如下
db.集合.insertOne(<JSON对象>) # 添加单个文档 不支持 explain命令
db.集合.insertMany([{<JSON对象1>},{<JSON对象2>}]) # 批量添加文档 不支持 explain命令
db.集合.insert() # 添加单个文档 支持 explain命令
那么我们随机插入一条文档 == [数据]
> db.members.insertOne({"name":"Google","url":"http://www.google.com"});
{
"acknowledged" : true,
"insertedId" : ObjectId("62752296f7fccd507cfc7ef1")
}
查看现有的集合 MongoDB可以像mysql一样查询表,当然也有他自己的查询所有的集合
> show tables
members
> show collections
members
大家可以发现在创建集合和文档的时候,我们并没有定义数据结构,如mysql 的int varchar 等,而是直接往上怼就行了,也是MongoDB的特色
查看文档中的所有数据
> db.members.find()
{ "_id" : ObjectId("62752296f7fccd507cfc7ef1"), "name" : "Google", "url" : "http://www.google.com" }
我们发现上面我们插入的数据信息为name 和url,居然多出了一个_id, 这个_id 类似mysql的主键一样的。默认为_id,当然我们可以自己指定主键的值。
> db.members.insert({"name":"SoSo","url":"http://www.SoSo.com","_id":10086})
WriteResult({ "nInserted" : 1 }) # 会返回写入是否成功
> db.members.find()
{ "_id" : ObjectId("62752296f7fccd507cfc7ef1"), "name" : "Google", "url" : "http://www.google.com" }
{ "_id" : 10086, "name" : "SoSo", "url" : "http://www.SoSo.com" }
在我们的认知中,索引是有序的,所有 默认生成的
_id的值肯定是有序的,id是由客户端来生成的
那么生产的东西其实就是一个时间戳
> ObjectId("62752296f7fccd507cfc7ef1").getTimestamp()
ISODate("2022-05-06T13:28:54Z")
有序插入{ordered:"ture"},顺序写入时,一旦遇到错误,便会退出,剩余的文档无论正确与否,都不会写入。乱序写入,则只要文档可以正确写入就会正确写入,不管前面的文档是否是错误的文档
> db.memebers.insertMany([{"_id":10087,"name":"4399","url":"http://www.4399.com"},{"_id":10087,"name":"7K7K","url":"http://www.7K7K.com"},{"_id":10088,"name":"aliyun","url":"http://www.aliyun.com"}],{ordered:"ture"});
uncaught exception: BulkWriteError({
"writeErrors" : [
{
"index" : 1,
"code" : 11000,
"errmsg" : "E11000 duplicate key error collection: demo.memebers index: _id_ dup key: { _id: 10087.0 }",
"op" : {
"_id" : 10087,
"name" : "7K7K",
"url" : "http://www.7K7K.com"
}
}
],
"writeConcernErrors" : [ ],
"nInserted" : 1,
"nUpserted" : 0,
"nMatched" : 0,
"nModified" : 0,
"nRemoved" : 0,
"upserted" : [ ]
}) :
BulkWriteError({
"writeErrors" : [
{
"index" : 1,
"code" : 11000,
"errmsg" : "E11000 duplicate key error collection: demo.memebers index: _id_ dup key: { _id: 10087.0 }",
"op" : {
"_id" : 10087,
"name" : "7K7K",
"url" : "http://www.7K7K.com"
}
}
],
"writeConcernErrors" : [ ],
"nInserted" : 1,
"nUpserted" : 0,
"nMatched" : 0,
"nModified" : 0,
"nRemoved" : 0,
"upserted" : [ ]
})
BulkWriteError@src/mongo/shell/bulk_api.js:371:48
BulkWriteResult/this.toError@src/mongo/shell/bulk_api.js:336:24
Bulk/this.execute@src/mongo/shell/bulk_api.js:1205:23
DBCollection.prototype.insertMany@src/mongo/shell/crud_api.js:326:5
@(shell):1:1
创建inventory集合并插入多个文档
MongoDB以集合(collection)的形式组织数据,collection 相当于关系型数据库中的表,如果collection不存在,当你对不存在的collection进行操作时,将会自动创建一个collection
db.inventory.insertMany([
{ item: "journal", qty: 25, status: "A", size: { h: 14, w: 21, uom: "cm" }, tags: [ "blank", "red" ] },
{ item: "notebook", qty: 50, status: "A", size: { h: 8.5, w: 11, uom: "in" }, tags: [ "red", "blank" ] },
{ item: "paper", qty: 10, status: "D", size: { h: 8.5, w: 11, uom: "in" }, tags: [ "red", "blank", "plain" ] },
{ item: "planner", qty: 0, status: "D", size: { h: 22.85, w: 30, uom: "cm" }, tags: [ "blank", "red" ] },
{ item: "postcard", qty: 45, status: "A", size: { h: 10, w: 15.25, uom: "cm" }, tags: [ "blue" ] }
]);
- db.inventory.find() 查询所有的文档
- db.inventory.find().pretty() 返回格式化后的文档
精准等值查询
查询"_id" 为 ObjectId(“6276164fd3204ee658022f4d”)
> db.inventory.find({"_id":ObjectId("6276164fd3204ee658022f4d")})
{ "_id" : ObjectId("6276164fd3204ee658022f4d"), "item" : "planner", "qty" : 0, "status" : "D", "size" : { "h" : 22.85, "w" : 30, "uom" : "cm" }, "tags" : [ "blank", "red" ] }
> db.inventory.find( { status: "D" } );
{ "_id" : ObjectId("6276164fd3204ee658022f4c"), "item" : "paper", "qty" : 10, "status" : "D", "size" : { "h" : 8.5, "w" : 11, "uom" : "in" }, "tags" : [ "red", "blank", "plain" ] }
{ "_id" : ObjectId("6276164fd3204ee658022f4d"), "item" : "planner", "qty" : 0, "status" : "D", "size" : { "h" : 22.85, "w" : 30, "uom" : "cm" }, "tags" : [ "blank", "red" ] }
多条件查询
> db.inventory.find( { qty: 0, status: "D" } );
{ "_id" : ObjectId("6276164fd3204ee658022f4d"), "item" : "planner", "qty" : 0, "status" : "D", "size" : { "h" : 22.85, "w" : 30, "uom" : "cm" }, "tags" : [ "blank", "red" ] }
嵌套对象精准查询
> db.inventory.find( { "size.uom": "in" } );
{ "_id" : ObjectId("6276164fd3204ee658022f4b"), "item" : "notebook", "qty" : 50, "status" : "A", "size" : { "h" : 8.5, "w" : 11, "uom" : "in" }, "tags" : [ "red", "blank" ] }
{ "_id" : ObjectId("6276164fd3204ee658022f4c"), "item" : "paper", "qty" : 10, "status" : "D", "size" : { "h" : 8.5, "w" : 11, "uom" : "in" }, "tags" : [ "red", "blank", "plain" ] }
返回指定字段
1:表示显示该字段,0表示不显示该字段,需要注意的是 那么有全是1,要全是0,不能混用.但主键KEY除外
> db.inventory.find( { }, { item: 1, status: 1 } );
{ "_id" : ObjectId("6276164fd3204ee658022f4a"), "item" : "journal", "status" : "A" }
{ "_id" : ObjectId("6276164fd3204ee658022f4b"), "item" : "notebook", "status" : "A" }
{ "_id" : ObjectId("6276164fd3204ee658022f4c"), "item" : "paper", "status" : "D" }
{ "_id" : ObjectId("6276164fd3204ee658022f4d"), "item" : "planner", "status" : "D" }
{ "_id" : ObjectId("6276164fd3204ee658022f4e"), "item" : "postcard", "status" : "A" }
> db.inventory.find( { }, { item: 0, status: 0 } );
{ "_id" : ObjectId("6276164fd3204ee658022f4a"), "qty" : 25, "size" : { "h" : 14, "w" : 21, "uom" : "cm" }, "tags" : [ "blank", "red" ] }
{ "_id" : ObjectId("6276164fd3204ee658022f4b"), "qty" : 50, "size" : { "h" : 8.5, "w" : 11, "uom" : "in" }, "tags" : [ "red", "blank" ] }
{ "_id" : ObjectId("6276164fd3204ee658022f4c"), "qty" : 10, "size" : { "h" : 8.5, "w" : 11, "uom" : "in" }, "tags" : [ "red", "blank", "plain" ] }
{ "_id" : ObjectId("6276164fd3204ee658022f4d"), "qty" : 0, "size" : { "h" : 22.85, "w" : 30, "uom" : "cm" }, "tags" : [ "blank", "red" ] }
{ "_id" : ObjectId("6276164fd3204ee658022f4e"), "qty" : 45, "size" : { "h" : 10, "w" : 15.25, "uom" : "cm" }, "tags" : [ "blue" ] }
> db.inventory.find( { }, { item: 1, status: 0 } );
Error: error: {
"ok" : 0,
"errmsg" : "Cannot do exclusion on field status in inclusion projection",
"code" : 31254,
"codeName" : "Location31254"
}
> db.inventory.find( { }, { _id: 1,item: 0, status: 0 } );
{ "_id" : ObjectId("6276164fd3204ee658022f4a"), "qty" : 25, "size" : { "h" : 14, "w" : 21, "uom" : "cm" }, "tags" : [ "blank", "red" ] }
{ "_id" : ObjectId("6276164fd3204ee658022f4b"), "qty" : 50, "size" : { "h" : 8.5, "w" : 11, "uom" : "in" }, "tags" : [ "red", "blank" ] }
{ "_id" : ObjectId("6276164fd3204ee658022f4c"), "qty" : 10, "size" : { "h" : 8.5, "w" : 11, "uom" : "in" }, "tags" : [ "red", "blank", "plain" ] }
{ "_id" : ObjectId("6276164fd3204ee658022f4d"), "qty" : 0, "size" : { "h" : 22.85, "w" : 30, "uom" : "cm" }, "tags" : [ "blank", "red" ] }
{ "_id" : ObjectId("6276164fd3204ee658022f4e"), "qty" : 45, "size" : { "h" : 10, "w" : 15.25, "uom" : "cm" }, "tags" : [ "blue" ] }
条件查询 and
寻找qty为45且status为A的文档
> db.inventory.find({$and:[{"qty":45},{"status":"A"}]}).pretty();
{
"_id" : ObjectId("6276164fd3204ee658022f4e"),
"item" : "postcard",
"qty" : 45,
"status" : "A",
"size" : {
"h" : 10,
"w" : 15.25,
"uom" : "cm"
},
"tags" : [
"blue"
]
}
条件查询 or
寻找qty为0或者status为A的文档
> db.inventory.find({$or:[{"qty":0},{"status":"A"}]})
{ "_id" : ObjectId("6276164fd3204ee658022f4a"), "item" : "journal", "qty" : 25, "status" : "A", "size" : { "h" : 14, "w" : 21, "uom" : "cm" }, "tags" : [ "blank", "red" ] }
{ "_id" : ObjectId("6276164fd3204ee658022f4b"), "item" : "notebook", "qty" : 50, "status" : "A", "size" : { "h" : 8.5, "w" : 11, "uom" : "in" }, "tags" : [ "red", "blank" ] }
{ "_id" : ObjectId("6276164fd3204ee658022f4d"), "item" : "planner", "qty" : 0, "status" : "D", "size" : { "h" : 22.85, "w" : 30, "uom" : "cm" }, "tags" : [ "blank", "red" ] }
{ "_id" : ObjectId("6276164fd3204ee658022f4e"), "item" : "postcard", "qty" : 45, "status" : "A", "size" : { "h" : 10, "w" : 15.25, "uom" : "cm" }, "tags" : [ "blue" ] }
Mongo查询条件和SQL查询对照表
| SQL | MONGOSQL |
|---|---|
| a<>1 或者 a!=1 | { a : {$ne: 1}} |
| a>1 | { a: {$gt:1}} |
| a>=1 | { a: {$gte:1}} |
| a<1 | { a: {$lt:1}} |
| a<=1 | { a: { $lte:1}} |
| in | { a: { $in:[ x, y, z]}} |
| not in | { a: { $nin:[ x, y, z]}} |
| a is null | { a: { $exists: false }} |
复合组件
主键可以是一个key,同时也可以是多个key,但是要注意的是复合主键的字段顺序换了,会当做不同的对象被创建,即使内容完全一致
> db.product.insertOne({"_id":{"product_name":1,"product_type":2},"supplierId":" 001","create_Time":"2022-05-07T07:22:43.409Z"})
{
"acknowledged" : true,
"insertedId" : {
"product_name" : 1,
"product_type" : 2
}
}
# 主键重复冲突
> db.product.insertOne({"_id":{"product_name":1,"product_type":2},"supplierId":" 001","create_Time":"2022-05-07T07:22:43.409Z"})
WriteError({
"index" : 0,
"code" : 11000,
"errmsg" : "E11000 duplicate key error collection: demo.product index: _id_ dup key: { _id: { product_name: 1.0, product_type: 2.0 } }",
"op" : {
"_id" : {
"product_name" : 1,
"product_type" : 2
},
"supplierId" : " 001",
"create_Time" : "2022-05-07T07:22:43.409Z"
}
}) :
WriteError({
"index" : 0,
"code" : 11000,
"errmsg" : "E11000 duplicate key error collection: demo.product index: _id_ dup key: { _id: { product_name: 1.0, product_type: 2.0 } }",
"op" : {
"_id" : {
"product_name" : 1,
"product_type" : 2
},
"supplierId" : " 001",
"create_Time" : "2022-05-07T07:22:43.409Z"
}
})
WriteError@src/mongo/shell/bulk_api.js:465:48
mergeBatchResults@src/mongo/shell/bulk_api.js:871:49
executeBatch@src/mongo/shell/bulk_api.js:940:13
Bulk/this.execute@src/mongo/shell/bulk_api.js:1182:21
DBCollection.prototype.insertOne@src/mongo/shell/crud_api.js:264:9
@(shell):1:1
# 换了key的顺序后还可以正常创建
> db.product.insertOne({"_id":{"product_type":2,"product_name":1},"supplierId":" 001","create_Time":"2022-05-07T07:22:43.409Z"})
{
"acknowledged" : true,
"insertedId" : {
"product_type" : 2,
"product_name" : 1
}
}
逻辑操作符匹配
-
$not: 匹配筛选条件不成立的文档{ field: { $not : { operator-expression} }}获取points 不小于100的,我们可以发现
$not也会筛选出并不包含查询字段的文档> db.members.find({points: { $not: { $lt: 100}}} ); { "_id" : ObjectId("62752296f7fccd507cfc7ef1"), "name" : "Google", "url" : "http://www.google.com" } { "_id" : 10086, "name" : "SoSo", "url" : "http://www.SoSo.com" } { "_id" : ObjectId("627620b4d3204ee658022f4f"), "nickName" : "曹操", "points" : 1000 } { "_id" : ObjectId("627620b4d3204ee658022f50"), "nickName" : "刘备", "points" : 500 } # 除去指定的字段 $exists:匹配包含查询字段的文档 > db.members.find({points: { $exists:true}}); { "_id" : ObjectId("627620b4d3204ee658022f4f"), "nickName" : "曹操", "points" : 1000 } { "_id" : ObjectId("627620b4d3204ee658022f50"), "nickName" : "刘备", "points" : 500 } -
$and: 匹配多个筛选条件同时满足的文档{ $and : [ condition expression1 , condition expression2 ..... ]}寻找昵称等于曹操, 积分大于 800 的文档,当作用在不同的字段上时 可以省略 $and
> db.members.find({$and : [ {nickName:{ $eq : "曹操"}}, {points:{ $gt:800}}]}); { "_id" : ObjectId("627620b4d3204ee658022f4f"), "nickName" : "曹操", "points" : 1000 } > db.members.find({nickName:{ $eq : "曹操"}, points:{ $gt:800}}); { "_id" : ObjectId("627620b4d3204ee658022f4f"), "nickName" : "曹操", "points" : 1000 } -
$or: 匹配至少一个筛选条件成立的文档{ $or :{ condition1, condition2, condition3,... }}
如果都是等值查询的话, $or 和 $in 结果是一样的
> db.members.find( {$or : [{nickName:{ $eq : "刘备"}},{points:{ $gt:1000}}]} );
{ "_id" : ObjectId("627620b4d3204ee658022f50"), "nickName" : "刘备", "points" : 500 }
$nor: 匹配多个筛选条件全部不满足的文档
文档游标
默认情况下 , 这里的count不会考虑 skip 和 limit的效果,如果希望考虑 limit 和 skip ,需要设置为 true。count的在分布式环境下要慎用,count 不保证数据的绝对正确
> db.members.count()
4
> db.members.count()
4
> db.members.find().skip(1).count()
4
> db.members.find().skip(1).count(true)
3
文档排序
cursor.sort(<doc>)
这里的<doc> 定义了排序的要求,1 表示由小到大, -1 表示逆向排序。当同时应用 sort, skip, limit 时 ,应用的顺序为 sort, skip, limit
> db.members.find().sort({points:1})
{ "_id" : ObjectId("62752296f7fccd507cfc7ef1"), "name" : "Google", "url" : "http://www.google.com" }
{ "_id" : 10086, "name" : "SoSo", "url" : "http://www.SoSo.com" }
{ "_id" : ObjectId("627620b4d3204ee658022f50"), "nickName" : "刘备", "points" : 500 }
{ "_id" : ObjectId("627620b4d3204ee658022f4f"), "nickName" : "曹操", "points" : 1000 }
> db.members.find().sort({points:-1})
{ "_id" : ObjectId("627620b4d3204ee658022f4f"), "nickName" : "曹操", "points" : 1000 }
{ "_id" : ObjectId("627620b4d3204ee658022f50"), "nickName" : "刘备", "points" : 500 }
{ "_id" : ObjectId("62752296f7fccd507cfc7ef1"), "name" : "Google", "url" : "http://www.google.com" }
{ "_id" : 10086, "name" : "SoSo", "url" : "http://www.SoSo.com" }
文档切片
可以使用 $slice 返回数组中的部分元素
- 1: 数组第一个元素
- -1:最后一个元素
- -2:最后两个元素
slice[ 1,2 ] : skip, limit 对应的关系
> db.members.insertOne({"_id":{"uid":3,"accountType":"qq"},"nickName":"张飞","points":1200,"address":[{"address":"xxx","post_no":0},{"address":"yyyyy","post_no":2}]})
{
"acknowledged" : true,
"insertedId" : {
"uid" : 3,
"accountType" : "qq"
}
}
# 返回数组的第一个元素 skip(4) 是为了排除不相关的数据,并无其他作用
> db.members.find({},{"_id":0,"nickName":1,"points":1,"address":{"$slice":1}}).skip(4)
{ "nickName" : "张飞", "points" : 1200, "address" : [ { "address" : "xxx", "post_no" : 0 } ] }
# 返回数组的第一个和第二个元素 skip(4) 是为了排除不相关的数据,并无其他作用
> db.members.find({},{"_id":0,"nickName":1,"points":1,"address":{"$slice":2}}).skip(4)
{ "nickName" : "张飞", "points" : 1200, "address" : [ { "address" : "xxx", "post_no" : 0 }, { "address" : "yyyyy", "post_no" : 2 } ] }
#返回倒数第一个 skip(4) 是为了排除不相关的数据,并无其他作用
> db.members.find({},{"_id":0,"nickName":1,"points":1,"address":{"$slice":-1}}).skip(4)
{ "nickName" : "张飞", "points" : 1200, "address" : [ { "address" : "yyyyy", "post_no" : 2 } ] }
数组元素的匹配
$elemMatch 和 $ 操作符可以返回数组字段中满足条件的第一个元素
#添加案例文档
> db.members.insertOne({"_id":{"uid":4,"accountType":"qq"},"nickName":"张三","points":1200,"tag":["student","00","IT"]})
{
"acknowledged" : true,
"insertedId" : {
"uid" : 4,
"accountType" : "qq"
}
#查询tag数组中第一个匹配"00" 的元素,.skip(5)目的为了删除干扰数据
> db.members.find({},{"_id":0,"nickName":1,"points":1,"tag":{"$elemMatch":{"$eq":"00"}}}).skip(5)
{ "nickName" : "张三", "points" : 1200, "tag" : [ "00" ] }
更新操作
updateOne/updateMany 方法要求更新条件部分必须具有以下之一,否则将报错
- $set: 给符合条件的文档新增一个字段,有该字段则修改其值
- $unset : 给符合条件的文档,删除一个字段
- $push: 增加一个对象到数组底部
- $pop:从数组底部删除一个对象
- $pull:如果匹配指定的值,从数组中删除相应的对象
- $pullAll:如果匹配任意的值,从数据中删除相应的对象
- $addToSet:如果不存在则增加一个值到数组
> db.useInfo.find()
{ "_id" : ObjectId("62762c5ed3204ee658022f51"), "name" : "zhansan", "tag" : [ "90", "Programmer", "PhotoGrapher" ] }
{ "_id" : ObjectId("62762c5ed3204ee658022f52"), "name" : "lisi", "tag" : [ "90", "Accountant", "PhotoGrapher" ] }
#将tag 中有90 的文档,增加一个字段: flag: 1
> db.useInfo.updateMany({tag:"90"},{$set:{flag:1}})
{ "acknowledged" : true, "matchedCount" : 2, "modifiedCount" : 2 }
> db.useInfo.find()
{ "_id" : ObjectId("62762c5ed3204ee658022f51"), "name" : "zhansan", "tag" : [ "90", "Programmer", "PhotoGrapher" ], "flag" : 1 }
{ "_id" : ObjectId("62762c5ed3204ee658022f52"), "name" : "lisi", "tag" : [ "90", "Accountant", "PhotoGrapher" ], "flag" : 1 }
# 只修改一个则用
> db.useInfo.updateOne({tag:"90"},{$set:{flag:2}})
{ "acknowledged" : true, "matchedCount" : 1, "modifiedCount" : 1 }
> db.useInfo.find()
{ "_id" : ObjectId("62762c5ed3204ee658022f51"), "name" : "zhansan", "tag" : [ "90", "Programmer", "PhotoGrapher" ], "flag" : 2 }
{ "_id" : ObjectId("62762c5ed3204ee658022f52"), "name" : "lisi", "tag" : [ "90", "Accountant", "PhotoGrapher" ], "flag" : 1 }
更新文档
db.collection.update(<query>,<update>,<options>)
<query>定义了更新时的筛选条件<update>文档提供了更新内容<options>声明了一些更新操作的参数
更新文档操作只会作用在第一个匹配的文档上,如果不包含任何更新操作符,则会直接使用update 文档替换集合中符合文档筛选条件的文档
更新操作符
-
$set 更新或新增字段
-
$unset删除字段
> db.useInfo.updateOne({tag:"90"},{$unset:{flag:2}}) { "acknowledged" : true, "matchedCount" : 1, "modifiedCount" : 1 } -
$rename 重命名字段
> db.useInfo.updateOne({"name":"lisi"},{$rename:{"name":"lisi2"}}) { "acknowledged" : true, "matchedCount" : 1, "modifiedCount" : 1 } -
$inc 加减字段值
-
$mul 相乘字段值
-
$min 采用最小值
-
$max 次用最大值
删除文档
db.collection.remove(<query>,<options>)
默认情况下,会删除所有满足条件的文档, 可以设定参数 { justOne:true},只会删除满足添加的第一条文档
> db.useInfo.find()
{ "_id" : ObjectId("62762c5ed3204ee658022f51"), "name" : "zhansan", "tag" : [ "90", "Programmer", "PhotoGrapher" ] }
{ "_id" : ObjectId("62762c5ed3204ee658022f52"), "tag" : [ "90", "Accountant", "PhotoGrapher" ], "flag" : 1, "lisi2" : "lisi" }
> db.useInfo.remove({},{justOne:true})
WriteResult({ "nRemoved" : 1 })
> db.useInfo.find()
{ "_id" : ObjectId("62762c5ed3204ee658022f52"), "tag" : [ "90", "Accountant", "PhotoGrapher" ], "flag" : 1, "lisi2" : "lisi" }
删除集合
db.collection.drop( { writeConcern:<doc>})
<doc>定义了本次删除集合操作的安全写级别 ,这个指令不但删除集合内的所有文档,且删除集合的索引
db.collection.remove只会删除所有的文档,直接使用remove删除所有文档效率比较低,可以使用 drop 删除集合,但是drop同时也会删除索引。

