
🌭MongoDB 索引原理及实战
索引的聚合: 👉 符合索引: 👉
1️⃣索引的引入
1.什么是索引?
索引是特殊的数据结构,它以一种易于遍历的形式存储集合数据集的一小部分。索引存储一个或一组特定字段的值,按字段的值排序。索引项的排序支持有效的相等匹配和基于范围的查询操作。此外,MongoDB可以通过使用索引中的排序返回排序后的结果。
2.B+Tree
比如基于 B+ tree 的索引数据结构图示如下:
单键索引,如基于主键ID 进行的B+ tree 数据结构
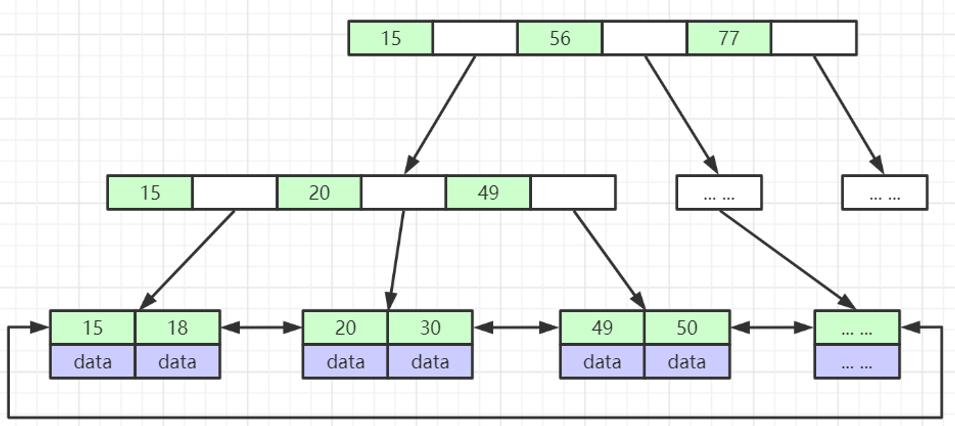
复合索引(复合索引只能支持前缀子查询)
基于name, age, position 建立的复合索引
name
name age
name age postion
age
age postion
3.索引的特点
- 索引支持更快的查询
- 更快的排序
2️⃣MongoDB的索引
1.MongoDB 具有默认的Id索引
在创建集合期间,MongoDB 在_id字段上创建唯一索引。该索引可防止客户端插入两个具有相同值的文档。你不能将_id字段上的index删除。默认不设置为时间戳的数据类型
> db.indexTest.insertOne({name:"1"})
{
"acknowledged" : true,
"insertedId" : ObjectId("62765012c16c79d26ec27f45")
}
# v 索引的版本 1 为升序的意思
> db.indexTest.getIndexes()
[ { "v" : 2, "key" : { "_id" : 1 }, "name" : "_id_" } ]
2.创建索引
db.collection.createIndex(<keys>, <options>)
<keys> 指定了创建索引的字段
# 设置了一个叫name的索引 并且是升序的
> db.members.createIndex({name:1});
{
"numIndexesBefore" : 1, # 创建本次索引之前有1个
"numIndexesAfter" : 2, # 创建本次索引之后有2个
"createdCollectionAutomatically" : false,
"ok" : 1
}
3.查看索引
# 再次查看索引信息
> db.members.getIndexes()
[
{
"v" : 2,
"key" : {
"_id" : 1
},
"name" : "_id_"
},
{
"v" : 2,
"key" : {
"name" : 1
},
"name" : "name_1"
}
]
和mysql 数据库一样mongdb的索引不是越多越好,索引的默认名称是索引键和索引中每个键的方向(即1或-1)的连接,使用下划线作为分隔符, 也可以通过指定 name 来自定义索引名称;如上面的索引名是name_1 也就是这个原因
但是我们也可以自己给索引命名,以便他人知道该索引使用的目的
> db.members.createIndex({age:1},{ name:"useLogSystem"});
{
"numIndexesBefore" : 2,
"numIndexesAfter" : 3,
"createdCollectionAutomatically" : false,
"ok" : 1
}
4.索引的删除
索引的删除主要有2中方式:
1.使用索引名称删除索引
> db.members.dropIndex("useLogSystem")
{ "nIndexesWas" : 3, "ok" : 1 }
2.使用索引定义删除索引
> db.members.dropIndex({name:1})
{ "nIndexesWas" : 2, "ok" : 1 }
5.索引的分析
和mysql 一样,mongdb 也有explain的操作,还是看winningPlan里面的内容:
💥 COLLSCAN :全集合扫描 == 全表扫描
> db.members.explain().find({name:"lisi"})
........
# 主要查看winningPlan
"winningPlan" : {
"stage" : "COLLSCAN",
"filter" : {
"name" : {
"$eq" : "lisi"
}
},
"direction" : "forward"
},
........
再次创建一个name 的增序索引并在解析一下,发现 stage发送了变化了
💥 FETCH 根据索引指向的文档的地址进行查询 —> IXSCAN 索引扫描
> db.members.createIndex({name:1})
> db.members.explain().find({name:"lisi"})
.......
"winningPlan" : {
"stage" : "FETCH",
"inputStage" : {
"stage" : "IXSCAN",
"keyPattern" : {
"name" : 1
},
"indexName" : "name_1",
"isMultiKey" : false,
......
那么在看看指定输出name 和 输出_id:
💥 PROJECTION_COVERED :内存覆盖 -----> 效率最高 并且不需要回表
> db.members.explain().find({name:"lisi"},{_id:0,name:1})
.......
"winningPlan" : {
"stage" : "PROJECTION_COVERED",
.......
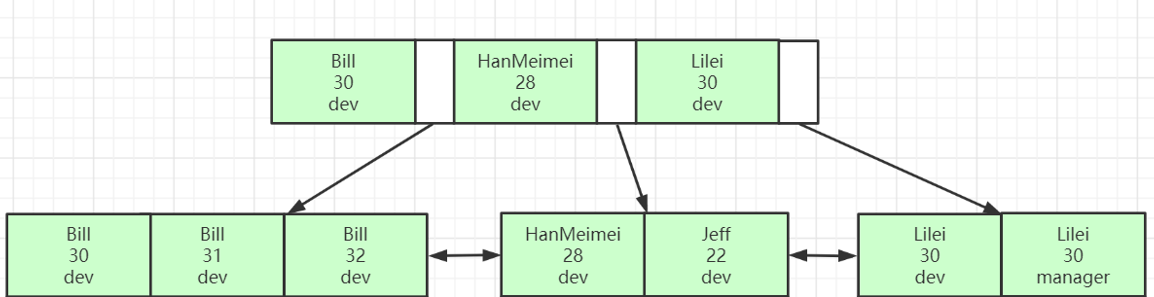
6.创建复合索引
MongoDB支持在多个字段上创建用户定义索引,即复合索引。
复合索引中列出的字段的顺序具有重要意义。如果一个复合索引由 {name: 1, age: -1} 组成,索引首先按name 升序排序,然后在每个name值内按 age 降序 排序。
那么先看看在没有索引的时候是什么情况?
> db.members.explain().find().sort({name:1,age:-1})
.......
"winningPlan" : {
"stage" : "SORT",
.......
💥 SORT: 需要再内存中排序,效率不高,同时消耗磁盘IO
再看看创建了复合索引以后
> db.members.createIndex({ name:1,age:-1});
{
"numIndexesBefore" : 2,
"numIndexesAfter" : 3,
"createdCollectionAutomatically" : false,
"ok" : 1
}
> db.members.explain().find().sort({name:1,age:-1})
.......
"winningPlan" : {
"stage" : "FETCH",
"inputStage" : {
"stage" : "IXSCAN",
.......
7.索引的唯一性
索引的unique属性使MongoDB拒绝索引字段的重复值。除了唯一性约束,唯一索引和MongoDB其他索引功能上是一致的
如果文档中的字段已经出现了重复值,则不可以创建该字段的唯一性索引
> db.members.createIndex({age:1},{unique:true});
{
"numIndexesBefore" : 1,
"numIndexesAfter" : 2,
"createdCollectionAutomatically" : false,
"ok" : 1
}
# 然后插入一个4399
> db.members.insertOne({"name":"4399"})
{
"acknowledged" : true,
"insertedId" : ObjectId("6276591bc16c79d26ec27f4a")
}
# 在插入一次4399 根据报错内容判断
> db.members.insertOne({"name":"4399"})
WriteError({
"index" : 0,
"code" : 11000,
"errmsg" : "E11000 duplicate key error collection: demo.members index: age_1 dup key: { age: null }",
"op" : {
"_id" : ObjectId("62765921c16c79d26ec27f4b"),
"name" : "4399"
}
如果新增的文档不具备加了唯一索引的字段,则只有第一个缺失该字段的文档可以被添加,索引中该键值被置为null。
> db.members.insertOne({"name1":"4399"})
WriteError({
"index" : 0,
"code" : 11000,
"errmsg" : "E11000 duplicate key error collection: demo.members index: age_1 dup key: { age: null }",
"op" : {
"_id" : ObjectId("627660b3c16c79d26ec27f4c"),
"name1" : "4399"
}
}) :
复合键索引也可以具有唯一性,这种情况下,不同的文档之间,其所包含的复合键字段值的组合不可以重复。
8.索引的稀疏性
索引的稀疏属性可确保索引仅包含具有索引字段的文档的条目。索引会跳过没有索引字段的文档。可以将稀疏索引与唯一索引结合使用,以防止插入索引字段值重复的文档,并跳过索引缺少索引字段的文档。
> db.sparsedemo.insertMany([{name:"xxx",age:19},{name:"zs",age:20}]);
{
"acknowledged" : true,
"insertedIds" : [
ObjectId("62766260c16c79d26ec27f4d"),
ObjectId("62766260c16c79d26ec27f4e")
]
}
> db.sparsedemo.find()
{ "_id" : ObjectId("62766260c16c79d26ec27f4d"), "name" : "xxx", "age" : 19 }
{ "_id" : ObjectId("62766260c16c79d26ec27f4e"), "name" : "zs", "age" : 20 }
创建 唯一键,稀疏索引
> db.sparsedemo.createIndex({name:1},{unique:true ,sparse:true});
{
"numIndexesBefore" : 1,
"numIndexesAfter" : 2,
"createdCollectionAutomatically" : false,
"ok" : 1
}
如果同一个索引既具有唯一性,又具有稀疏性,就可以保存多篇缺失索引键值的文档了
> db.sparsedemo.insertOne({age:20});
{
"acknowledged" : true,
"insertedId" : ObjectId("627662fcc16c79d26ec27f51")
}
> db.sparsedemo.insertOne({name:"dddd"});
{
"acknowledged" : true,
"insertedId" : ObjectId("62766312c16c79d26ec27f53")
}
说明:如果只单纯的 唯一键索引,则 缺失索引键的字段,只能有一个!复合键索引也可以具有稀疏性,在这种情况下,只有在缺失复合键所包含的所有字段的情况下,文档才不会被加入到索引中。
9.索引的生存时间
针对日期字段,或者包含了日期元素的数组字段,可以使用设定了生存时间的索引,来自动删除字段值超过生存时间的文档。
# 构造数据
> db.members.find()
{ "_id" : ObjectId("627664a6c16c79d26ec27f54"), "name" : "zhangsanss", "age" : 19, "tags" : [ "00", "It", "SH" ], "create_time" : ISODate("2022-05-07T12:23:02.928Z") }
# 创建索引 在create_time字段上面创建了一个生存时间是30s的索引
> db.members.createIndex({ create_time: 1},{expireAfterSeconds:30 });
{
"numIndexesBefore" : 1,
"numIndexesAfter" : 2,
"createdCollectionAutomatically" : false,
"ok" : 1
}

10.复合键索引不具备生存时间的特性
当索引键是包含日期元素的数组字段时,数组中最小的日期将被用来计算文档是否已经过期。数据库使用一个后台线程来监测和删除过期的文档,删除操作可能会有一定的延迟

